

Big tech companies are facing a big problem as they try to make smarter AI models: there’s not enough data on the internet. A report from The Wall Street Journal talks about how there’s going to be less and less data available to teach AI, which is making companies look for other places to get data.
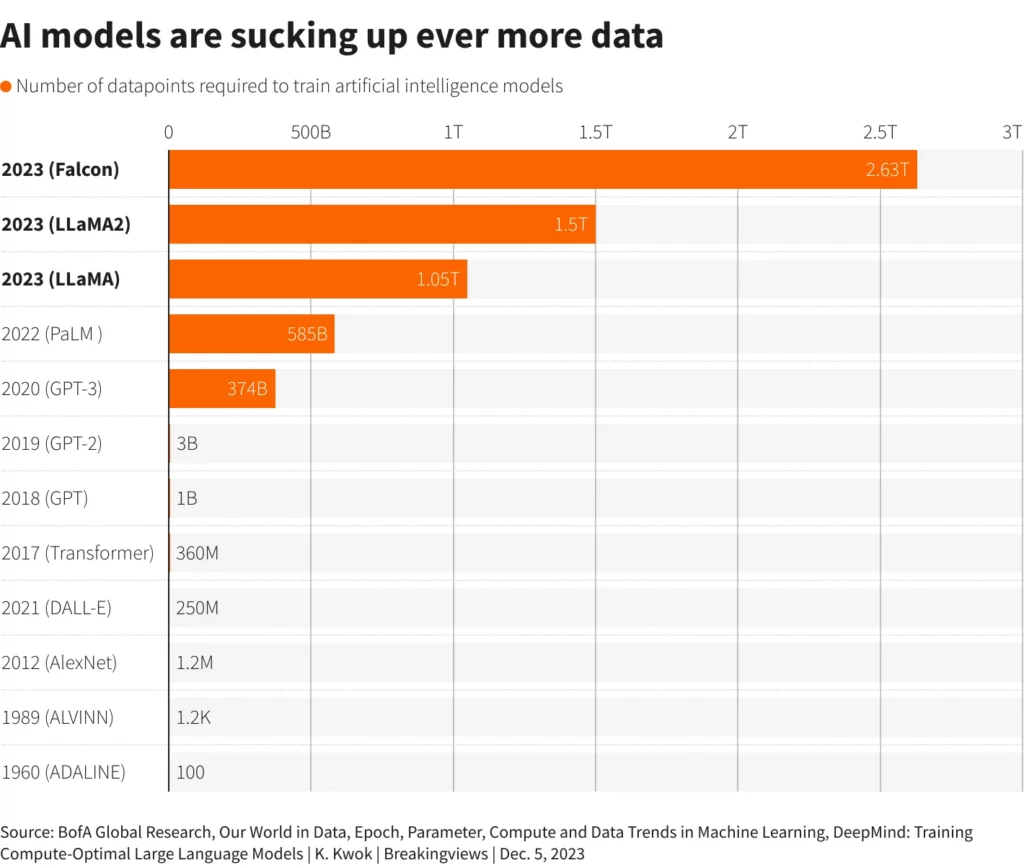
Epoch researcher Pablo Villalobos tells the Wall Street Journal that OpenAI trained GPT-4 on roughly 12 million tokens, which are words and portions of words broken down in ways the LLM can understand. (OpenAI says one token is about .75 words, so 12 million tokens is roughly nine million words.)
“The biggest uncertainty,” Villalobos said, “is what breakthroughs you’ll see.”
Villalobos believes that GPT-5, OpenAI’s next big model, would need 60 to 100 trillion tokens to keep up with the expected growth. That’s 45 to 75 trillion words, per OpenAI’s count. The kicker? Villalobos says after exhausting all the possible high-quality data available on the internet, you’d still need anywhere from 10 to 20 trillion tokens or even more.
With the usual internet data running low, AI companies are looking at different places for information. They’re checking out things like transcripts from videos online and making their own data using AI. But this change brings its own problems, like the risk of AI models getting confused because they’re using data made by computers instead of real stuff.
According to FirstPost, Relying on synthetic data has made some people in the tech world worried. Experts are warning about a problem they call “digital inbreeding.” This happens when AI models trained on synthetic data start having stability issues, which can make them perform poorly.
As there’s not enough data to train AI models, big companies like OpenAI are trying out new ways to train them. One idea they’re thinking about is using transcriptions from YouTube videos to teach their GPT-5 model. But this raises some worries about both technical problems and legal issues.
Even though there are challenges, companies like OpenAI and Anthropic are working hard to make synthetic data better. They want to improve its quality so that it can help train AI models even when there’s not enough real data available. Although they haven’t shared exactly how they’re doing it, their goal is to create synthetic data that’s really good and can keep AI training going strong.
In November 2023, Tech Times said that AI companies were close to running out of really good data to train their models with. Now, months later, it looks like this problem is still around and getting worse.
Even though some people worry about not having enough data, many experts are hopeful that new technology can help solve this problem. While some predictions say there might not be enough data to train AI models, improvements in AI research give us hope that we can find ways to fix this issue.








